Experience tracking with mlflow
With Mlflow tracking you can organize all your ML project experiences in one single platform. Read the article to know more and click the github icon to access the repo.
Mlflow is an open source tool backed by databricks. It works with several languages such as R, python and Java. It was designed to be multiuser and integrates easily with Apache Spark. It has 3 main blocks:
- MLflow Tracking
- MLflow Projects
- MLflow Models
Wine dataset example
Wine dataset was collected in the North Region of Portugal and has the goal of predicting the wine's quality based on chemical features. [source]

Please check the github icon for full code and analysis.
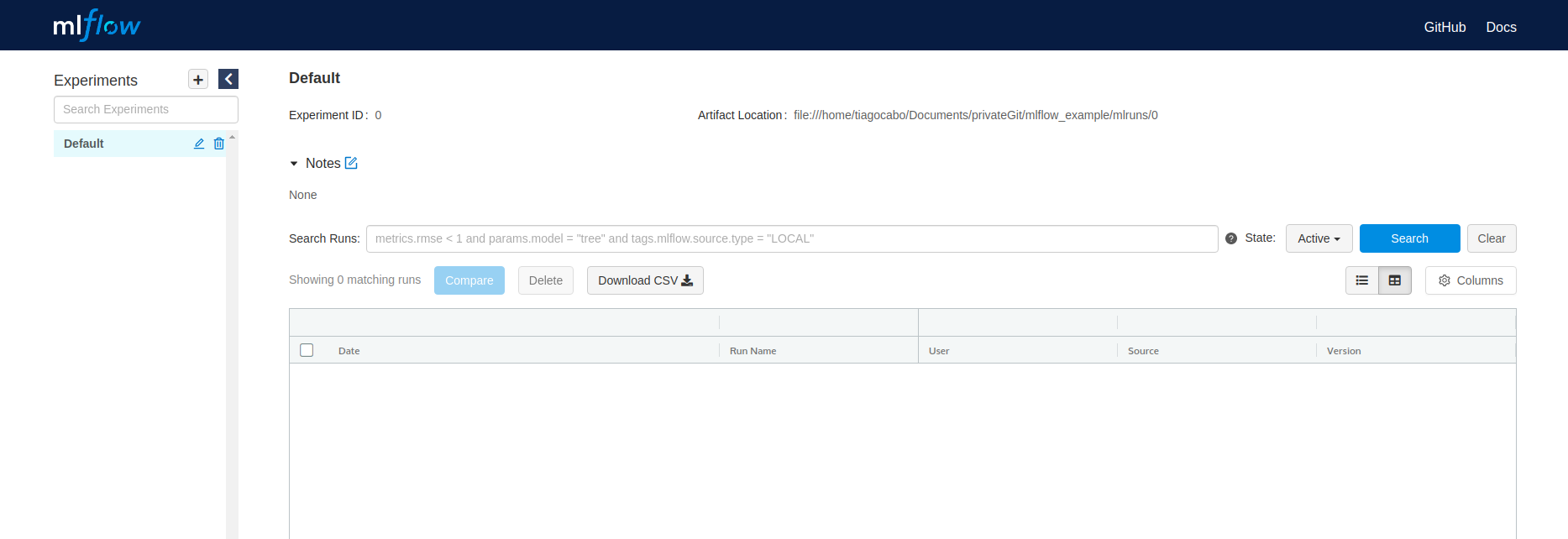
MLflow step1 - Setup + UI
After installing mlflow using the console select your desire directory and run mlflow ui.pip install mlflow
mlflow uiAfter initiating the ui you should see an image like this
Mlflow step2 - run the first experience
MLflow provides some methods to configurate the mlflow session, like:
- mlflow.set_tracking_uri('http://xx.xx.x.xx:5000') This is very useful when you have the mlflow client, running on a server. Which is something I recommend, in order for your colleages to have access your results.
- mlflow.set_experiment("Elastic Net") With this method you are able to create sections, in order to better organize the experiences
- mlflow.start_run('name') The goal of this command is just to setup up a new run. You can also give it a name.
- mlflow.set_tag("mlflow.note.content", "Greed search") With this method you can add note contents to your runs. This is very helpfull in order for you keep track of small details of your experience that may not be expressed in the metrics/parameters/artifacts
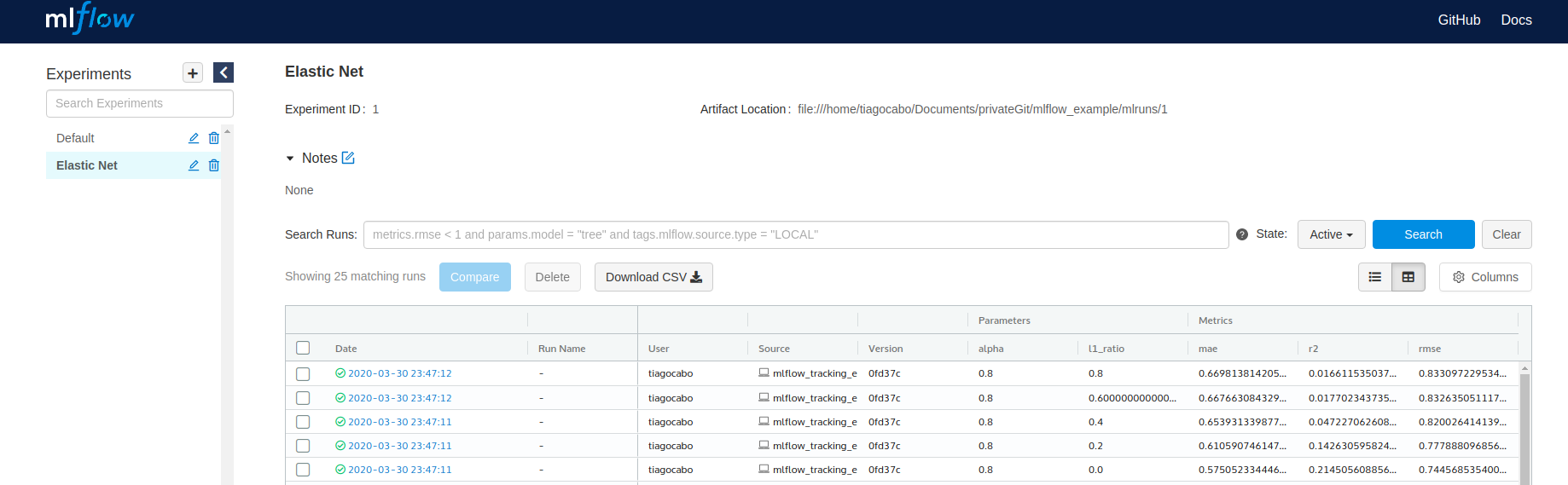
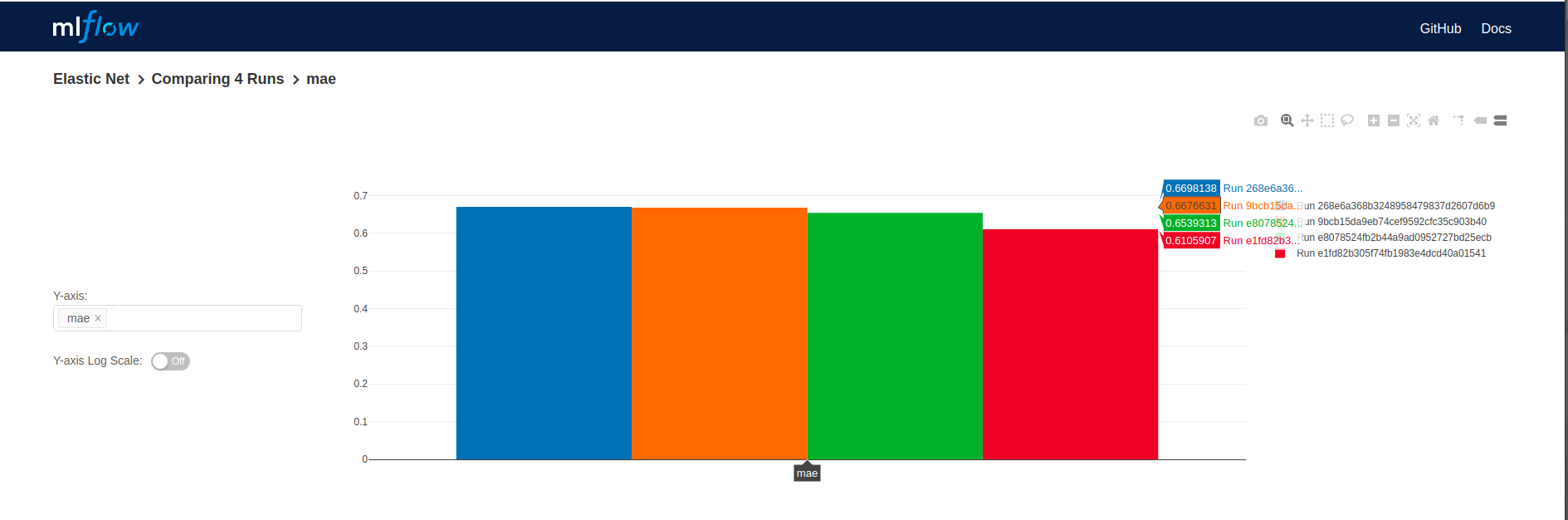
- mlflow.log_params('name', object, step)
- mlflow.log_metrics('name', object, step)
- mlflow.log_artifacts('name', object, step)
Tips
In case you use a problem with epochs, I advise you to use the step params, because it will allow you a better comparison between epock. The same could be used in k fold validationimport mlflow
mlflow.log_metrics('name', variable, step)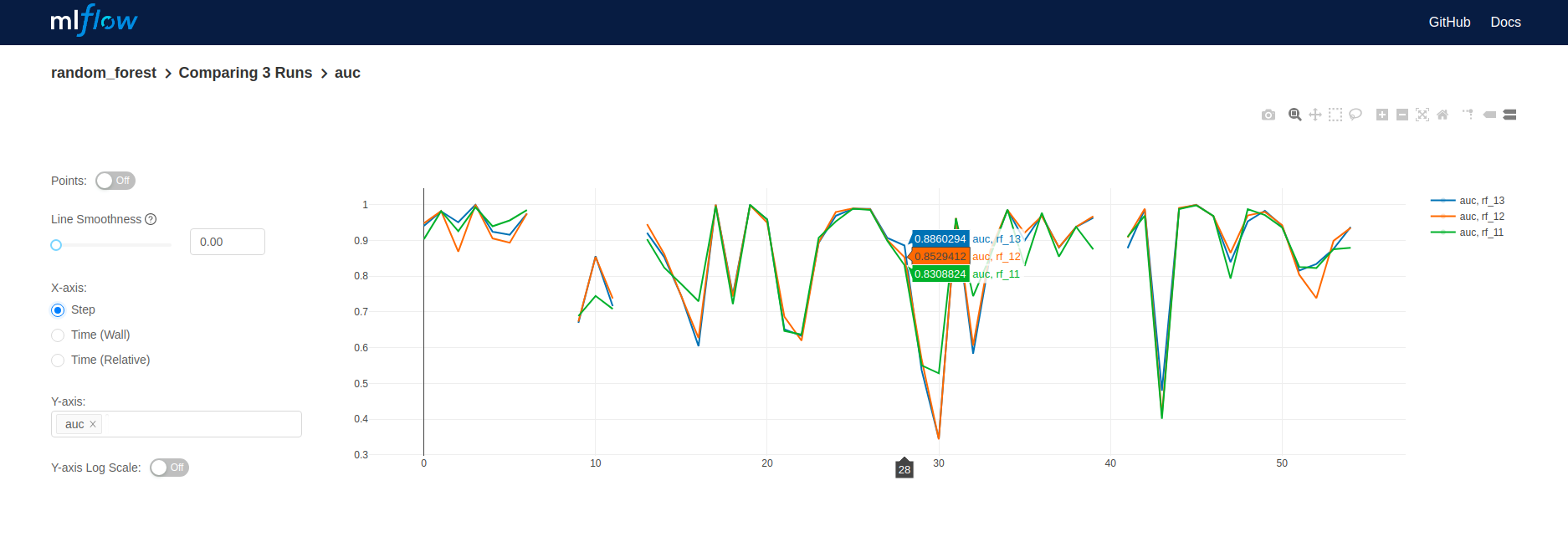
To sum up
MLFlow is a tool of activily developent, with great features. I currently use MLflow tracking on my daily bases. I found this tool when I start to have a lot of experiences, I felt lost between all the natebooks.
Tiago Cabo